Trong thế giới rộng lớn của cảnh sống kỹ thuật số, web crawler đóng vai trò quan trọng trong việc thu thập và tổ chức thông tin từ khắp nơi trên web. GPTBot web crawler của OpenAI là một ví dụ điển hình về công cụ như vậy, được thiết kế để thu thập kiến thức và nâng cao khả năng của các mô hình AI như ChatGPT. Tuy nhiên, không phải ai cũng chào đón sự hiện diện của web crawler này trên website của họ, và các nỗ lực để ngăn chặn nó đã gây ra cuộc tranh luận về quyền riêng tư dữ liệu, sở hữu trí tuệ và bảo mật website. Trong bài viết này, chúng ta sẽ khám phá thế giới của web crawling, tìm hiểu cách GPTBot hoạt động và cung cấp những bước cụ thể cho chủ sở hữu website để bảo vệ tài sản trực tuyến của họ.
Understanding Web Crawling
The Anatomy of a Web Crawler
Tại bản chất, một web crawler – còn được gọi là spider hoặc bot của công cụ tìm kiếm – là một chương trình tự động điều hướng trên không gian rộng lớn của internet, lùng sục các trang web để thu thập thông tin. Nó tổ chức thông tin này theo cách có cấu trúc, dễ dàng truy cập bởi các công cụ tìm kiếm. Hãy tưởng tượng nó như một thủ thư chăm chỉ đang lập danh mục cho thư viện rộng lớn của internet.
The Function of Web Crawlers
Web crawler thực hiện nhiệm vụ quan trọng là lập chỉ mục cho mỗi trang web có URL liên quan, tập trung vào các trang web có uy tín và liên quan đến các truy vấn tìm kiếm cụ thể. Ví dụ, nếu bạn đang tìm kiếm một giải pháp cho một lỗi Windows, web crawler của công cụ tìm kiếm bạn chọn sẽ lục qua các URL từ các trang web được coi là uy tín về lỗi Windows.
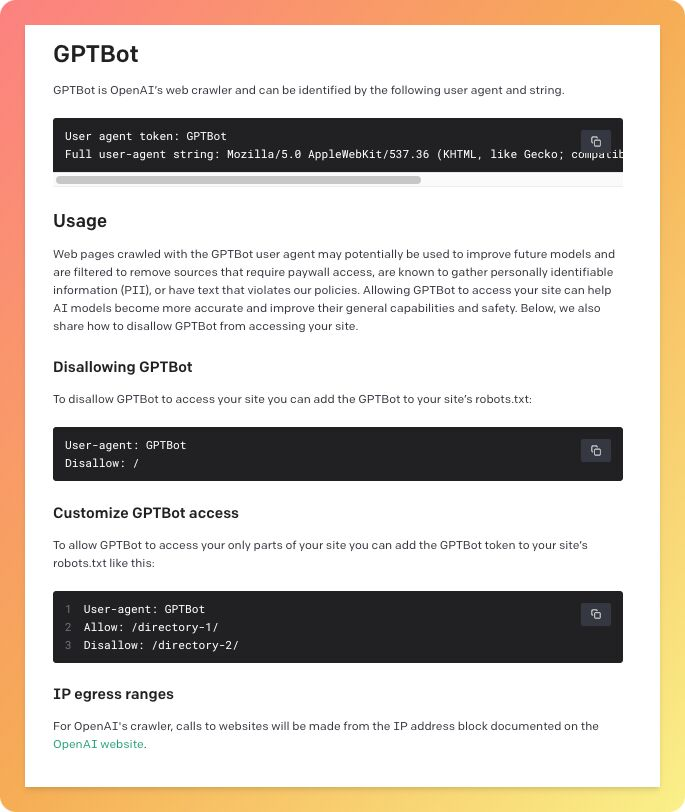
OpenAI’s GPTBot Web Crawler
GPTBot của OpenAI, một web crawling bot, đã được phát triển để cải tiến các mô hình AI như ChatGPT. Bằng cách thu thập dữ liệu từ các trang web, nó giúp huấn luyện các mô hình AI trở nên an toàn hơn, chính xác hơn và có khả năng rộng hơn. Nó có khả năng nhận diện và trích xuất thông tin hữu ích từ các trang web, giúp nó góp phần vào sự phát triển của công nghệ AI.
The Need for Website Protection
The Clash of Interests
Trong khi người dùng đón nhận các mô hình AI như ChatGPT vì sự giàu có thông tin của chúng, chủ sở hữu website có quan điểm khác nhau. Việc phát hành GPTBot đã gây ra những lo ngại đối với những người tạo ra website, người lo lắng về việc sử dụng tiềm năng của nội dung của họ mà không có sự công nhận hoặc lượt truy cập website thích hợp. Tình thế này làm nổi bật sự cân nhắc tinh tế giữa sự tiến bộ của AI và việc tôn trọng quyền sở hữu nội dung của người tạo nội dung.
What Can the robots.txt File Do?
Tệp robots.txt cung cấp một mức độ kiểm soát về hành vi của GPTBot trên trang web của bạn. Dưới đây là một số hành động mà nó có thể thực hiện:
Completely Block GPTBot
Bằng cách cấu hình tệp robots.txt, bạn có thể ngăn chặn GPTBot truy cập toàn bộ website của mình. Điều này hữu ích nếu bạn muốn duy trì mức độ riêng tư tối đa.
Block Specific Pages
Nếu có những trang cụ thể trên website của bạn mà bạn muốn giấu khỏi ánh mắt tò mò của GPTBot, bạn có thể chỉ định những trang đó trong tệp robots.txt. Điều này cho phép bạn duy trì sự cân nhắc giữa quyền riêng tư và việc truyền đạt thông tin.
Define Links GPTBot Can Follow
Tệp robots.txt cũng có thể hướng dẫn cho việc điều hướng của GPTBot bằng cách chỉ ra những liên kết nó có thể theo dõi và những liên kết nó nên tránh.
How To Protect Your Website From OpenAI’s Web Crawler?
Để kiểm soát hoạt động của GPTBot trên website của bạn, hãy làm theo các bước sau:
Complete Blocking
- Thiết lập tệp robots.txt trên máy chủ website của bạn.
- Chỉnh sửa tệp bằng công cụ chỉnh sửa văn bản.
- Thêm các dòng sau để ngăn GPTBot truy cập: User-agent: GPTBot Disallow: /
Blocking Specific Pages
- Thiết lập tệp robots.txt trên máy chủ website của bạn.
- Chỉnh sửa tệp bằng công cụ chỉnh sửa văn bản.
- Để chặn các thư mục cụ thể, sử dụng các dòng như: User-agent: GPTBot Allow: /directory-1/ Disallow: /directory-2/
The Power of Choice: Opt-Out and Protection
OpenAI’s Opt-Out Option
OpenAI công nhận những lo ngại của chủ sở hữu website và cung cấp một cơ chế cho phép họ rời bỏ. Điều này cho phép người tạo ra website có quyền quyết định cách mà nội dung của họ được sử dụng và truy cập bởi các mô hình AI.
Safeguarding Your Digital Realm
Để bảo vệ website của bạn khỏi GPTBot web crawler của OpenAI và đảm bảo nội dung trực tuyến của bạn vẫn nằm dưới sự kiểm soát của bạn, hãy xem xét những bước sau:
- Tùy chỉnh robots.txt: Sử dụng tệp robots.txt để điều chỉnh quyền truy cập của GPTBot, sử dụng lệnh “Disallow: /” để ngăn truy cập.
- Kiểm soát truy cập tùy chỉnh: Tùy chỉnh quyền truy cập của GPTBot bằng cách sử dụng chỉ thị tùy chỉnh trong tệp robots.txt, quy định trang nào mà bot có thể khám phá.
- Tường lửa ứng dụng web (WAF): Đầu tư vào một WAF để thêm một lớp bảo mật bổ sung cho website của bạn, hiệu quả chống lại các mối đe dọa trực tuyến khác nhau, bao gồm cả web crawler.
- Giám sát lưu lượng: Theo dõi định kỳ mẫu lưu lượng trang web của bạn để phát hiện các đỉnh không bình thường hoặc mẫu, điều này có thể chỉ ra hoạt động crawling không mong muốn.
Bằng cách triển khai các chiến lược này, bạn có thể bảo vệ hiệu quả website của mình khỏi GPTBot web crawler của OpenAI và duy trì quyền kiểm soát trên miền kỹ thuật số của bạn.
Conclusion
Web crawler đóng vai trò quan trọng trong việc thu thập thông tin từ internet, và GPTBot của OpenAI là một ví dụ điển hình. Tuy nhiên, việc bảo vệ website trước GPTBot đã trở thành một vấn đề được quan tâm đặc biệt đối với chủ sở hữu website. Sử dụng tệp robots.txt và các biện pháp bảo mật khác, chủ sở hữu website có thể bảo vệ tài sản trực tuyến của mình khỏi GPTBot và duy trì quyền kiểm soát trên nội dung của họ. Việc tạo ra sự cân nhắc giữa tiến bộ của AI và quyền riêng tư và sở hữu của người tạo nội dung là cần thiết để đảm bảo sự phát triển bền vững của cả hai lĩnh vực này.
Nguồn tham khảo: 1